print(df_lda)Se hace un modelado de tópicos en un corpus de resúmenes de artículos científicos sometidos a la revista Madera y bosques, primero generando una matriz de términos de documentos (Document Term Matrix), filtrada por los valores de tf_idf (term frequency_inverse document frequency), sobre la cual se corre un algoritmo de Latent Dirichlet Allocation, con el paquete topicmodels.
Descripción de la base de datos
La base de datos provista, una vez limpiada filtrados los registros vacíos y con una limpieza general de espacios en blanco es la siguiente:
Depuración de idiomas
Como vienen en distintos idiomas, haremos una detección de idioma para determinar qué haremos con los datos; sin embargo, hay una problemática importante: hay resúmenes que están presentados un inglés y luego en español, en la misma celda, entonces comparamos las primeras y las últimas 100 letras de cada texto y tomemos solo aquellos en que ambas sean español
Entonces nos quedamos con un corpus de 883 artículos en español, que representan el 90% de los textos.
Proceso de texto
Ya una vez que contamos con el corpus final de artículos en español depurados, procedemos a tokenizar, es decir, dividir cada palabra del texto, para después quitar las stopwords que son las palabras extremadamente comunes, como que, como, de, a, quienes y que contribuyen poco al significado del texto.
Además calculamos la term frequency-inverse document frequency que es un estadístico que compara la frecuencia de una palabra en un texto versus la frecuencia de esa misma palabra en todos los textos, nuestra base de datos finalmente se ve así:
latent dirichlet allocation
Previamente a suministrar el dataframe al algoritmo, filtramos a aquellos registros que tienen una tf_idf mayor a 0.01, para aligerar el proceso; después convertimos a un objeto clase DocumentTermMatrix y finalmente corremos el algoritmo LDA
Ahora hacemos una visualización del modelo de tópicos, en la que se ve
Aquí podemos ver que empiezan a emerger algunos tópicos, como el 1, que puede ser servicios ambientales, o el 2, como biomasa y carbono, el 16 diversidad y comunidad, etc.
Siguiendo la regla de que
un tópico es un conjunto de palabras y un documento es un conjunto de tópicos
hay documentos que, filtrándolos por un valor alto de gamma, presentan adscripción a más de un tópico:
df_doc_topics |>
group_by(document) |>
top_n(3, gamma) |> ungroup() |> arrange(document) |> filter(gamma > 1e-1)El dataframe con los 15 términos más usados por tópico es el siguiente:
df_topics %>%
group_by(topic) %>%
top_n(15, beta) %>%
ungroup() %>%
arrange(topic) |> mutate(id = rep(seq(1,15), 20) ) |> select(-beta) |>
pivot_wider(names_from = topic, values_from = term) |> select(-id) Visualizaciones de los tópicos de MyB en el tiempo y el espacio
Previo a hacer visualizaciones, asignamos nombres a los tópicos, para ofrecer algo más informativo que un número, tras una rápida nominación tenemos los siguientes nombres para cada tópico:
2016, el segundo año del periodo, fue el de mayor número de artículos recibidos, con 295, lo que da la impresión de una disminución en los siguientes años; además, 2023 apenas lleva 2 meses completos transcurridos a la fecha de este análisis, con esta tendencia debería llegar a más de 60 artículos este año.
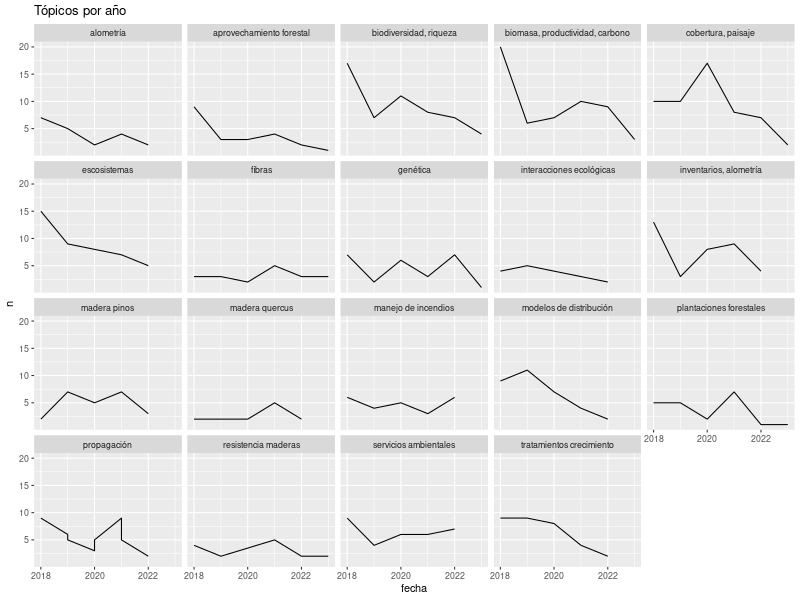 Por el pico en 2016, todos los tópicos aparentan una disminución, vemos que “biodiversidad, riqueza”, “biomasa, productividad, carbono” y “cobertura, paisaje” son los que más publicaciones tienen a lo largo del tiempo.
Por el pico en 2016, todos los tópicos aparentan una disminución, vemos que “biodiversidad, riqueza”, “biomasa, productividad, carbono” y “cobertura, paisaje” son los que más publicaciones tienen a lo largo del tiempo.
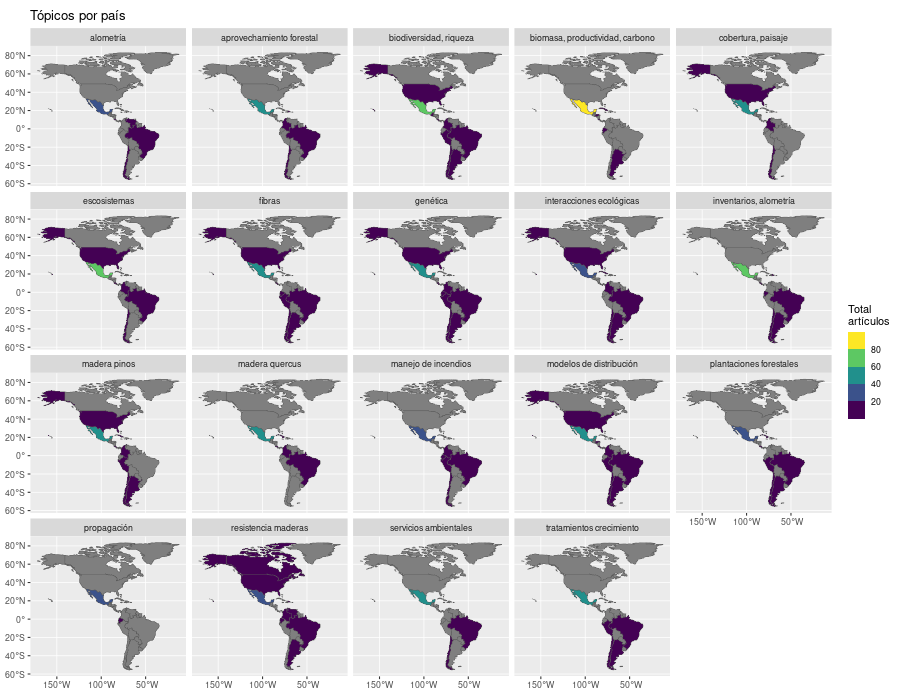
En el mapa se aprecia la predominancia de los autores mexicanos, lo cual es natural en una revista mexicana, además de tener publicaciones en cada uno de los tópicos; los temas más difundidos son “biomasa, productividad, carbono”, “plantaciones forestales” y “tratamientos crecimiento”.