La minería o análisis de texto consiste en encontrar significado en documentos literarios, periodísticos, tweets… a través de procesos estadísticos e informáticos, para buscar sentimientos, jerarquías, agrupamientos, similitudes, diferencias, elementos importantes del texto -como nombres y lugares- e incluso estilos de escritura.
En este post (esperemos que sea el primero de un análisis más profundo) exploraremos la columna de opinión en La Jornada de Víctor Toledo, el Titular de la SEMARNAT, nombrado hace apenas un par de meses, para tener una ventana hacia su visión de la ecología, la ciencia y las comunidades y otros temas que irán emergiendo a través de este análisis.
Para hacer este post usamos las siguientes técnicas de minería de datos:
Web scrapping para obtener todas las columnas de opinión de Victor Toledo (>180) y organizarlas tabularmente Análisis de Posición de Discurso, para ver el papel que cumple cada palabra en una oración (verbos, adverbios, preposiciones, …) Lematización, para agrupar conceptualmente palabras que provengan de una raíz, como raíz y radicular :p. Preparación: remover palabras muy comunes y símbolos de puntuación que aporten poco significado al documento, como “que”, “para”, “esto”. Reconocimiento de Entidades Nominadas: hacer uso de inteligencia artificial para reconocer personas, lugares y organizaciones en el texto. Agrupamiento de documentos, para ver cuáles son los temas en general que Toledo ha abordado más en sus columnas. *Estadísticas de frecuencia, para resaltar palabras clave en ciertos temas, que sean claves para diferenciarlos de otros.
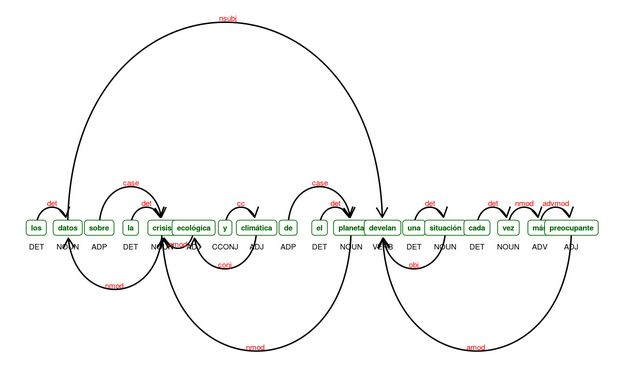
El análisis de texto parte del reconocimiento de la función de cada palabra en una oración, para determinar relaciones entre palabras y a partir de esto ensamblar el resto del análisis de oraciones, buscando sentimientos, actores, lugares. En la siguiente gráfica tenemos un esquema de una oración, para ver cómo los programas encuentran relaciones y funciones de cada palabra en el contexto de una oración; el texto es un extracto de la última entrega de Toledo, “Los ‘científicos’ y la 4T: oposición ilegítima”. Vemos, por ejemplo, como reconoce que la acción “develar”, sobre el objeto “situación”, la llevan a cabo los “datos”, a pesar de su distancia en el texto. Nota: La función separa “del” en “de” y “el”.
Ahora echemos un vistazo al archivo que scrappeamos de jornada.com:
Vemos una columna con el nombre del autor, otra con el título de la columna de aquel día, otra columna con el cuerpo del texto y finalmente la url de dsdescarga (así lo configuré en python para descargar e integrar) Desde Python, usando el módulo spacy procesamos el primer archivo, para obtener lo siguiente:
Donde en la primer columna tenemos el título del texto, de ahí los tokens o elementos mínimos que tienen significado por sí solos (a diferencia de una palabra atomizada a sus letras), en otras columnas el lema o raíz, la part of speech o la función en la oración de cada palabra (determinante, adjetivo, sustantivo, etc.) y finalmente si es una stopword: palabras muy comunes con poco valor semántico, como “qué”, “mientras”.
Ahora agregamos el tf_idf que es un estadístico de cuánto se usa un término en un documento y cuánto se usa en el cuerpo total de documentos, esto para ayudarnos a encontrar las palabras clave que diferencian entre sí a las columnas de opinión de Toledo en La Jornada
Ahora emplearemos una técnica de machine learning, del conjunto de procesos que se conocen como inteligencia artificial, que nos sirve para agrupar todos los textos, sin que nosotros tengamos que aportar etiquetas del texto, en n categorías que podemos elegir, en este caso usamos 8.
Podemos ver algúna consistencia en las palabras de cada grupo, y determinar un tópico que las englobe, en el caso del grupo 1, son documentos que tratan de procesos electorales, el segundo caso tiene que ver con diversidad biológica vs cultivos de soya, el tercero con políticas de AMLO. Vemos Monsanto en el quinto grupo y trangénicos en el octavo, por lo cual podemos sugerir que hicimos grupos en exceso; por lo pronto, sigamos con el análisis exploratorio.
¿Cómo han ido apareciendo en el tiempo los tópicos? El tópico 1, el de elecciones, tuvo un pico en 2012, concidente con las elecciones presidenciales de aquel año, el 3, que incluye el nombre de AMLO y sus componentes, ha tenido más documentos después de las elecciones de 2018. Están filtrados a solo los términos que tengan una alta pertenencia a ese tópico (> 0.5).
Ahora hagamos un análisis más supervisado y menos elaborado, solo pasándole una lista de palabras que los que hemos leído a Toledo conocemos como parte distintiva de sus textos, para ver con qué frecuencia las usa.
En la gráfica de arriba mostramos el porcentaje que ocupaba cada palabra en el total del texto de Toledo de cada año; vemos que “agua” y “comunidades” son, de los términos que escogimos, los más importantes en las columnas de opinión del secretario.
Al texto también podemos agruparlo en clusters, para ver qué palabras ocurren en los mismos documentos, en la gráfica se aprecian varios grupos muy lógicos, como “universidades-tecnológicos” o “municipal-estatal”, y otros conjuntos de palabras que conforman unidades semánticas, como “soberanía-alimentaria” y “organismos-internacionales”, estas entidades son reconocibles con técnicas que veremos más adelante. La imagen de abajo es solo una ramificación del enorme cluster de miles de palabras.
Podemos también hacer lo opuesto: agrupar documentos en función de las palabras que utilizan, para tener conjuntos cercanos en sus conceptos; en la imagen vemos agrupados documentos con títulos similares (el agrupamiento se hizo con el contenido, no con el encabezado): “la ciencia y la defensa biocultural de México” con “la resistencia es biocultural: el caso de los mayas”. En un cluster la altura nos indica qué tan cercanos son los textos, mientras menor sea este valor, serán más parecidos, ese es el caso de los títulos que cambié por B1,B2 y B3, que apuntan a los títulos: “¿Qué es hoy un gobierno de izquierda?”,“El glamoroso encanto de la ecología”, “La crisis de la civilización moderna”, que si bien no son idénticos, al filtrar por palabras con alta presencia en el cuerpo de documentos, anular su orden para solo tomar su cantidad y eliminar las stopwords, quedan sin diferencia en este análisis. Solo se presenta la 21 ramificación del árbol, a un 92% de esparcido de términos en la matriz
Otra técnica muy útil es el reconocimiento de entidades nominadas, que mediante técnicas de inteligencia artificial busca entidades, comprendidas estas como localidades (municipios, estados, países, …), personas, organizaciones, fechas. En este caso, usando el programa sin entrenarlo con nuestros datos da unos resultados interesantes en reconocer estos elementos: vemos que solo la palabra “morena” está mal ubicada en entidades, esto es por el modo en que venía en el texto y por el material -páginas de wikipedia- con el que fue entrenado el modelo de reconocimiento; en organizaciones solo la palabra “estado” está mal ubicada, se reconocen partidos políticos y marcas en la lista; vemos en nombres también un nivel decente de reconocimiento, si tomamos en cuenta que solo usamos la función out of the box. También hay que resaltar que si bien sólo aparecen solo los primeros nombres de personas (en este caso Francisco es por el Papa), es por el filtro a los 15 con más registros; spacy reconoció, entre otros, a Paul Crutzen, Jason W. Moore, Jorge Reichmann, Estelina López Gómez y Samir Flores entre otros.
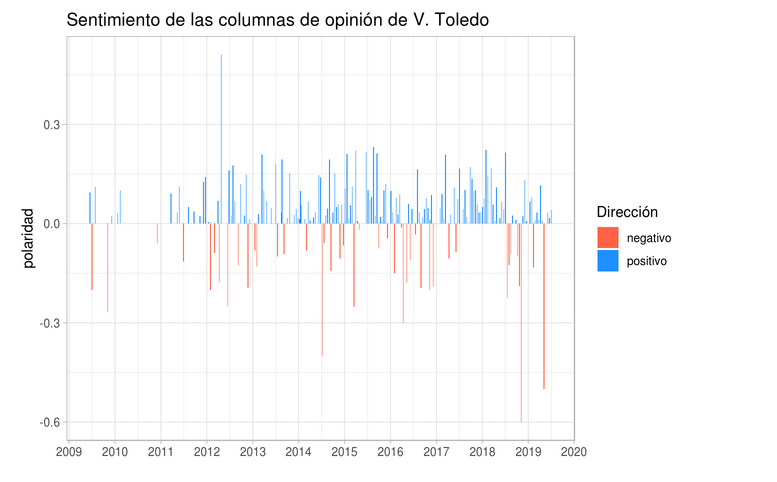
Terminamos este post con análisis de sentimiento, el cual utiliza un diccionario al cual previamente se le han asignado valores numéricos de -1 a 1, donde palabras como “pésimo” estén valoradas como negativas y “excelente” como positivas; también se hace uso de amplificadores, como “muy”, “demasiado”, “algo” y redireccionadores, como “no” o “nunca”, cuando anteceden a una palabra, para no catalogar “nunca interesante” como un sentimiento positivo.
En los documentos de Toledo, vemos una tendencia a escritos más negativos conforme pasaba el tiempo; el mayor nivel de negatividad lo encontramos en la nota El NAIM y las plumas perfumadas de los académicos, al leerla saltan a la vista adjetivos como “limitadas”, “rabiosamente”, “descalificando”, “falsedad”, “desastre”… Si bien buena parte del texto usa las palabras de los aludidos, el final es muy corrosivo:
Se trata de tres “plumas perfumadas” que contribuyen a la inercia institucional puesta al servicio de las élites a las que pertenecen. Sus opiniones son tan superficiales, que en vez de contribuir a un debate serio, abonan a la confusión movidos por sus propios tropismos reaccionarios. Nada de análisis, nada de ponderaciones, nada de contextos, para entender un asunto complejo, sólo reacciones estomacales o hepáticas.